| 1C |
Garykom, RomanYS, АгентБезопаснойНацио, Михаил Козлов, PR, RVN, Fedor-1971, Bigbro, Группа неравнодушных, Terrixus, Redaktor, ndrv, глазковыколупыватель, Lazy Stranger, 2S, craxx, Seriy_Volk, T32, piter3, maxab72, alexela, DrZombi, phabeZ, H A D G E H O G s, strange2007, Масянька, privetik, vicof, Hawk_1c, Mafiozaa, СвинТуз, AntiBuh, mmg, abfm, Ёпрст, Буковка, nick86, Rovan, Zapal, dimm7310, bushd, elka302, Chameleon1980
☑
26.05.25
✎
15:28
привет!
Есть табличная часть документа Заказ в производство (в которой есть колонки ID и значение), и есть массив значений ( содержащий только ID). Как правильно обойти элементы ТЧ чтобы все строки с совпадающими ID получили значение 1 (скрин)?
Если бы табличная часть сравнивалась с одним элементом массива, была бы связь один ко многим (один элемент массива к строкам ТЧ). Тут все легко. А Как действовать в случае связи многие ко многим?
Обходить ТЧ и внутри каждого элемента ТЧ делать цикл на сравнение с одним из элементов массива?
Есть табличная часть документа Заказ в производство (в которой есть колонки ID и значение), и есть массив значений ( содержащий только ID). Как правильно обойти элементы ТЧ чтобы все строки с совпадающими ID получили значение 1 (скрин)?
Если бы табличная часть сравнивалась с одним элементом массива, была бы связь один ко многим (один элемент массива к строкам ТЧ). Тут все легко. А Как действовать в случае связи многие ко многим?
Обходить ТЧ и внутри каждого элемента ТЧ делать цикл на сравнение с одним из элементов массива?

|
26.05.25
✎
15:31
Обходить массив значений а строки из Заказа отбирать по фильтру по ИД.
26.05.25
✎
15:32
MergeJoin
27.05.25
✎
10:50
(0) Не совсем понятно что нужно
1. Есть массив ИД
2. Есть таблица значений (ТЧ Заказа в производство) с ИД и Значением
Что собрался делать?
Заполнять некую другую ТЧ по ИД выдавать там значение из п.2?
Проверять, что для ИД из п.1 заполнены все значения в таблице из п.2? (решение предложено в (1))
1. Есть массив ИД
2. Есть таблица значений (ТЧ Заказа в производство) с ИД и Значением
Что собрался делать?
Заполнять некую другую ТЧ по ИД выдавать там значение из п.2?
Проверять, что для ИД из п.1 заполнены все значения в таблице из п.2? (решение предложено в (1))
27.05.25
✎
14:22
Если обойти, а не загнать в запрос,
то видимо "НайтиСтроки"
то видимо "НайтиСтроки"
27.05.25
✎
14:23
Можно отсортировать по ключу и идти синхронно по двум таблицам
27.05.25
✎
14:24
+ тупой перебор
27.05.25
✎
14:25
Итого как минимум четыре способа
Есть и еще
"Барометр" короче от Нильса Бора
Есть и еще
"Барометр" короче от Нильса Бора
гуру
27.05.25
✎
14:30
(9) Сортировка это тоже затраты
гуру
27.05.25
✎
15:21
(0) Засунуть массив в ТЗ, передать в запрос, соединить
гуру
27.05.25
✎
14:33
(13)+ Хотя парю, если надо просто 1 для совпадающих строк то прямо массив передаем в запрос
И делаем условие ID В(&Массив)
И делаем условие ID В(&Массив)
27.05.25
✎
14:33
(9) Это называется СоединениеСлиянием, MergeJoin.
Вот тут даже алгоритм есть, прям на русском.
wiki:Алгоритм_соединения_слиянием_сортированных_списков
Вот тут даже алгоритм есть, прям на русском.
wiki:Алгоритм_соединения_слиянием_сортированных_списков
гуру
27.05.25
✎
14:34
(15) Еще один
А затраты на сортировку???
А затраты на сортировку???
гуру
27.05.25
✎
14:42
Для целочисленных ID при наличии дофига памяти и (Макс(ID)-Мин(ID)) укладывается в нее
Наиболее быстрый алгоритм это однопроходный алгоритм на простых массивах (не которые 1С а напрямую в памяти)
Сначала по массиву значений, пишем 1 в ПростойМассив[ID]
Затем по ТЧ, тупо смотрим ?(ПростойМассив[ID] = 1, 1, 0)
Наиболее быстрый алгоритм это однопроходный алгоритм на простых массивах (не которые 1С а напрямую в памяти)
Сначала по массиву значений, пишем 1 в ПростойМассив[ID]
Затем по ТЧ, тупо смотрим ?(ПростойМассив[ID] = 1, 1, 0)
28.05.25
✎
09:12
(17)
Типа соответствие? Номер строки в первой ключ. Значение массив строк во второй. Или массив номеров?
Типа соответствие? Номер строки в первой ключ. Значение массив строк во второй. Или массив номеров?
28.05.25
✎
09:58
1. Простейший вариант. ТЧ обходим, в массиве ищем (Мас.Найти(...))
1+. Тоже самое, но массив заменяем на соотвествие
2. Если значений в массиве заведомо мало (это не случай из (0)). Обходим массив и ТЧ.НайтиСтроки()
3,4... Мерджи, соединение запросом и прочее. Тоже не случай ТС
1+. Тоже самое, но массив заменяем на соотвествие
2. Если значений в массиве заведомо мало (это не случай из (0)). Обходим массив и ТЧ.НайтиСтроки()
3,4... Мерджи, соединение запросом и прочее. Тоже не случай ТС
гуру
28.05.25
✎
11:24
(19) поиск в массиве или соответствии с 5 лямов элементов?
обрати внимание на ID в (0)
обрати внимание на ID в (0)
28.05.25
✎
11:30
(20) То, что макс. значение ID 5+ млн, вовсе не означает, что столько значений в выборке.
При 5 млн строк речи про ТЧ бы вообще не было.
Ну и в соответствии это будет вполне приемлемо, если конечно не повторять 5 млн раз)
При 5 млн строк речи про ТЧ бы вообще не было.
Ну и в соответствии это будет вполне приемлемо, если конечно не повторять 5 млн раз)
гуру
28.05.25
✎
11:33
(21) допустим в ТЧ 100к строк
а в массиве значений с ID 1 лям элементов
?
а в массиве значений с ID 1 лям элементов
?
28.05.25
✎
11:48
(22)

|
28.05.25
✎
11:49
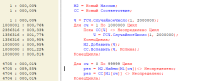
(22) 0.27 секунд на 100000 поисков норм результат?

|
28.05.25
✎
12:03
(22) а вот поиск по аналогичному массиву (1 млн элементов) в 3000 медленнее
|
гуру
28.05.25
✎
12:10
(23) (24) нормальный, пойдет
Соответствие в 1С это индексированная HashMap по сути
Соответствие в 1С это индексированная HashMap по сути
гуру
28.05.25
✎
12:11
(25) угу как раз к Массив.Найти у меня была претензия
гуру
28.05.25
✎
12:18
(25) проверь еще:
&НаСервере Процедура Команда2НаСервере() М1 = Новый Массив; ГСЧ = Новый ГенераторСлучайныхЧисел(ТекущаяУниверсальнаяДатаВМиллисекундах()); Для Сч = 1 По 100000 Цикл М1.Добавить(ГСЧ.СлучайноеЧисло(1, 2000000)); КонецЦикла; ММ = Новый Массив(3000000); Для Сч = 1 По 1000000 Цикл ММ[ГСЧ.СлучайноеЧисло(1, 2000000)] = Истина; КонецЦикла; Для Сч = 0 По 99999 Цикл Рез = ММ[М1[Сч]] <> Неопределено; КонецЦикла; КонецПроцедуры
28.05.25
✎
12:49
(28) такой вариант в два раза быстрее соответствия. Но ограничения слишком жесткие:
- ИД тольео неотрицательные целые числа
- память придётся пропорционально максимальному значению ИД, а не их реальному количеству.
- ИД тольео неотрицательные целые числа
- память придётся пропорционально максимальному значению ИД, а не их реальному количеству.
гуру
28.05.25
✎
12:57
(29) на самом деле такой вариант не в два раза а примерно на порядок быстрее
просто в 1С массивы по сути связные списки а не обычные простейшие массивы в выделенной памяти
просто в 1С массивы по сути связные списки а не обычные простейшие массивы в выделенной памяти
гуру
28.05.25
✎
13:00
(29)
- ИД тольео неотрицательные целые числа
нет, можно любые даже строки привести к целым
- память придётся пропорционально максимальному значению ИД, а не их реальному количеству.
в реальных задачах ИД обычно последовательные 28.05.25
✎
13:02
(30) Ну мы же про 1С говорим. Для массива типизированных значений (не 1С) понятно, что сложность получения по индексу массива O(1), а сложность проверки по map O(log(N))
гуру
28.05.25
✎
13:03
(32) угу я пробовал в 1С вместо массива заюзать COMSafeArray
получилась какая-то хрень
получилась какая-то хрень
28.05.25
✎
13:05
(31) "в реальных задачах ИД обычно последовательные"
ХЗ. В типовых уже полно мест, где в качестве ИД используется ГУИД.
В общем использование соответствия для многочисленного поиска можно считать отраслевым стандартом
ХЗ. В типовых уже полно мест, где в качестве ИД используется ГУИД.
В общем использование соответствия для многочисленного поиска можно считать отраслевым стандартом
гуру
28.05.25
✎
13:06
(34) хе, насчет УИД
попробуй свой код на УИДах вместо целых ID
попробуй свой код на УИДах вместо целых ID
28.05.25
✎
13:18
(35) Какие-то сомнения? Соответствия будут работать
гуру
28.05.25
✎
13:19
(36) конечно будут, только тормозней
28.05.25
✎
13:23
(37) Ничего подобного 0.23 секунды
